Yuanrenxue.com recives any estimated n/a unique visitors and n/a unique page views per day. Revenue gained from these much visits may be n/a per day from various advertising sources. The estimated worth of site is n/a.
- Website Age
n/a
- Alexa Rank no-data
- Country
 China
China
- IP Address
106.12.149.97
google ads
HTML SIZE INFORMATION
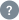
Text / Code Ratio
23.77 %
yuanrenxue.com has a website text/code ratio of 23.77 %. Search engine crawlers tend to not pick up pages with inadequate content.
IMPORTANT HTML TAGS AND COUNTS

H1
| No |
Text |
| 1 |
猿人学python 教你挣钱的python教程网站 |
H2
| No |
Text |
| 1 |
如何让python爬虫一天抓取100万张网页 |
| 2 |
分享我曾经的学习和找工作经历 |
| 3 |
利用爬虫挣钱系列2-细说数据整合 |
| 4 |
个人利用python爬虫技术怎么挣钱-10万被动收入 |
| 5 |
分析app的登陆协议 |
| 6 |
正式把猿人学爬虫高阶课放在网课平台了 |
| 7 |
某文app逆向抓取分析 |
| 8 |
我出了一套爬虫高阶学习课 |
| 9 |
Python 的控制流代码混淆 |
| 10 |
Android 7.0 https抓包单双向验证解决方案汇总 |
| 11 |
如何抽取上千家新闻网站正文 |
| 12 |
App爬虫-双向认证抓包的两种方法 |
| 13 |
Python 教你动态展示微博热搜排名变化 |
| 14 |
Protobuf协议逆向解析-app爬虫 |
| 15 |
爬虫之-某生鲜app加密参数逆向分析 |
| 16 |
Python教你全自动抢微信红包 |
| 17 |
做独立博客如何挣钱-挣钱系列 |
| 18 |
巧用numpy切分图片 |
| 19 |
来通过写技术文章挣钱 |
| 20 |
今年对于我来说好坏参半 |
| 21 |
搞定某app的tcp抓包,并直接调用so文件进行hook抓取 |
| 22 |
爬虫挣钱系列-结构化商标信息挣被动收入的可能性 |
| 23 |
用python如何统计文本文件中的词频?(python练习) |
| 24 |
使用frida rpc不还原token算法抓取app最简单的hook方法 |
H3
| No |
Text |
| 1 |
猿人学python公众号 |
| 2 |
猿人学python阅读排行 |
| 3 |
友情链接 |
H4
| No |
Text |
| 1 |
我出了一套爬虫高阶学习课 |
| 2 |
某文app逆向抓取分析 |
| 3 |
正式把猿人学爬虫高阶课放在网课平台了 |
| 4 |
分析app的登陆协议 |
Text Styling
- STRONG0
- B3
- EM0
- I63
- U0
- CITE0
B
| No |
Text |
| 1 |
猿人学Python公众号 |
| 2 |
猿人学Python阅读排行 |
| 3 |
友情链接 |
I
| No |
Text |
| 1 |
|
| 2 |
(20) |
| 3 |
(20) |
| 4 |
(20) |
| 5 |
|
| 6 |
|
LINK ANALYSIS
Total Link Count: 129
Internal Link Count
: 108 
| No |
Text |
Type |
| 1 |
Python教程 |
text |
| 2 |
Python爬虫 |
text |
| 3 |
Python Selenium教程 |
text |
| 4 |
Python爬虫挣钱 |
text |
| 5 |
APP抓取 |
text |
| 6 |
Python技术杂谈 |
text |
| 7 |
|
text |
| 8 |
- |
empty |
| 9 |
如何让Python爬虫一天抓取100万张网页 |
text |
| 10 |
王平 |
text |
| 11 |
阅读详情 |
text |
| 12 |
分享我曾经的学习和找工作经历 |
text |
| 13 |
利用爬虫挣钱系列2-细说数据整合 |
text |
| 14 |
个人利用Python爬虫技术怎么挣钱-10万被动收入 |
text |
| 15 |
APP抓取 |
text |
| 16 |
- |
empty |
| 17 |
分析app的登陆协议 |
text |
| 18 |
王平 |
text |
| 19 |
APP抓取 |
text |
| 20 |
- |
empty |
| 21 |
正式把猿人学爬虫高阶课放在网课平台了 |
text |
| 22 |
王平 |
text |
| 23 |
APP抓取 |
text |
| 24 |
- |
empty |
| 25 |
某文APP逆向抓取分析 |
text |
| 26 |
王平 |
text |
| 27 |
Python爬虫 |
text |
| 28 |
- |
empty |
| 29 |
我出了一套爬虫高阶学习课 |
text |
| 30 |
王平 |
text |
| 31 |
Python技术杂谈 |
text |
| 32 |
- |
empty |
| 33 |
Python 的控制流代码混淆 |
text |
| 34 |
王平 |
text |
| 35 |
APP抓取 |
text |
| 36 |
- |
empty |
| 37 |
Android 7.0 Https抓包单双向验证解决方案汇总 |
text |
| 38 |
王平 |
text |
| 39 |
Python爬虫 |
text |
| 40 |
- |
empty |
| 41 |
如何抽取上千家新闻网站正文 |
text |
| 42 |
王平 |
text |
| 43 |
APP抓取 |
text |
| 44 |
- |
empty |
| 45 |
APP爬虫-双向认证抓包的两种方法 |
text |
| 46 |
王平 |
text |
| 47 |
Python技术杂谈 |
text |
| 48 |
- |
empty |
| 49 |
Python 教你动态展示微博热搜排名变化 |
text |
| 50 |
王平 |
text |
External Link Count
: 21
| No |
Text |
Type |
| 1 |
李金龙 |
text |
| 2 |
linux培训 |
text |
| 3 |
我爱代码 |
text |
| 4 |
C++技术网 |
text |
| 5 |
Laravel学院 |
text |
| 6 |
java1234博客 |
text |
| 7 |
一点php |
text |
| 8 |
前端开发者 |
text |
| 9 |
ui设计培训 |
text |
| 10 |
技术拉近你我 |
text |
| 11 |
春哥技术源码论坛 |
text |
| 12 |
雷雪松的博客 |
text |
| 13 |
红色石头的博客 |
text |
| 14 |
崔庆才的博客 |
text |
| 15 |
菜鸟博客 |
text |
| 16 |
架构师 |
text |
| 17 |
一起开源 |
text |
| 18 |
八零IT人 |
text |
| 19 |
周立的博客 |
text |
| 20 |
oldpan |
text |
| 21 |
蜀ICP备18020009号-3 |
text |
Nofollow Link Count
: 2
| No |
Text |
Type |
| 1 |
|
image |
| 2 |
蜀ICP备18020009号-3 |
text |
Title Link Count
: 0
WEBSITE SERVER INFORMATION
- Service Provider (ISP)
- Beijing Baidu Netcom Science and Technology Co., Ltd.
- Hosted IP Address
- 106.12.149.97
- Hosted Country
- China
- Host Region
- Jiangsu , Suzhou
- Latitude and Longitude
- 31.299 : 120.585



 Yuanrenxue.com
Yuanrenxue.com


 Azerbaijan
Azerbaijan Bahrain
Bahrain Libyan Arab Jamah...
Libyan Arab Jamah... Trinidad and Toba...
Trinidad and Toba... Jamaica
Jamaica Jersey
Jersey Rwanda
Rwanda Gibraltar
Gibraltar Nepal
Nepal Brazil
Brazil Cs.gettysburg.edu
Cs.gettysburg.edu
 Pokepark-Kanto.co.jp
Pokepark-Kanto.co.jp Qualityfestas.com.br
Qualityfestas.com.br Widgets.thesports01.com
Widgets.thesports01.com E7.i.lencr.org
E7.i.lencr.org Gp*****sion.github.io
Gp*****sion.github.io Isohunts.to
Isohunts.to Some-Stuffs.com
Some-Stuffs.com 1337X.to
1337X.to E3Expo.com
E3Expo.com Spiral-Ssk.ru
Spiral-Ssk.ru
 Conwayschools.org
Conwayschools.org Zdravietyo.com
Zdravietyo.com
 Innotalks.ir
Innotalks.ir
 Leechpremium.link
Leechpremium.link Poolstoreandmore.com
Poolstoreandmore.com Provytvarniky.cz
Provytvarniky.cz
 Pinoyartist.com
Pinoyartist.com Synergy.ru
Synergy.ru Ah.fm
Ah.fm Comando.la
Comando.la Xfilmestorrents.com.br
Xfilmestorrents.com.br